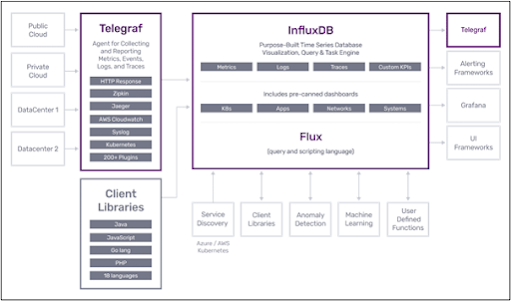
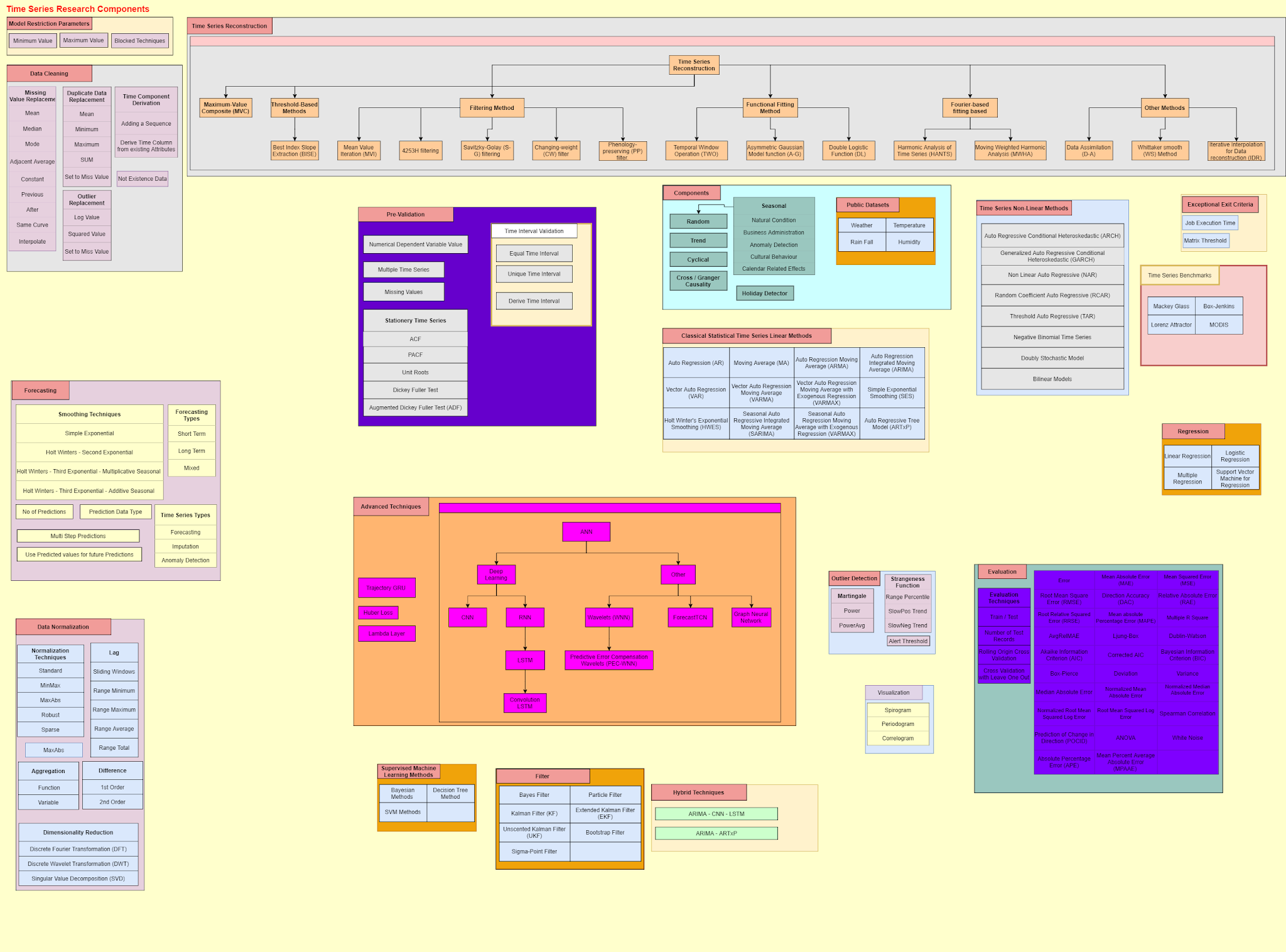
As we know, clustering is an unsupervised technique. When it comes to classification, there are a lot of evaluation techniques such as Precision, Recall, F1, MCC etc. However, what are the techniques that can be used to evaluate clustering techniques. Purity calculation is one of the simplest calculations to evaluate your clusters.
In the Purity cluster quality measure, we will analyse the cluster distribution with respect to a selected variable. Let us look at how to calculate Purity in a Text Clustering using Orange and the following is the Orage flow.
Further, you can get the Orange flow from
Github.
First, let us look at how the Purity is calculated.
Let us assume that following are the clusters and data distribution.
In each cluster, the maximum number of objects that are falling to each cluster is calculated. For example, in Cluster 1, X has three instances while Cluster 2 has three instances of O and Cluster 3 has four L instances. Those numbers are added up and divided by the total number of instances which is 16.
Let us look at this example with our popular film review dataset.
After the text Preprocessing, the Loving Clustering technique is used. Following is the cluster distribution with respect to the review classification.
So the Purity is (190 + 193 + 158 + 123+ 136 + 112+124+102 +11) / 2000. Ideally, this should be close to 1 meanwhile in the case of multi-class we can calculate the Purity with a Minimum value which should be close to 0.
Entropy is another calculation that is performed to measure the Cluster Quality which we will leave for another day.