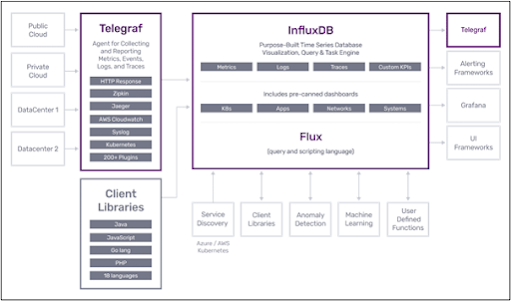
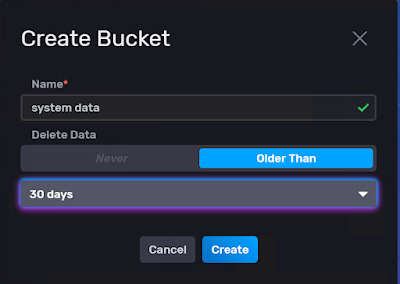
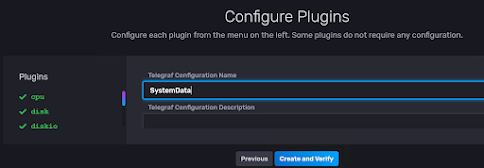
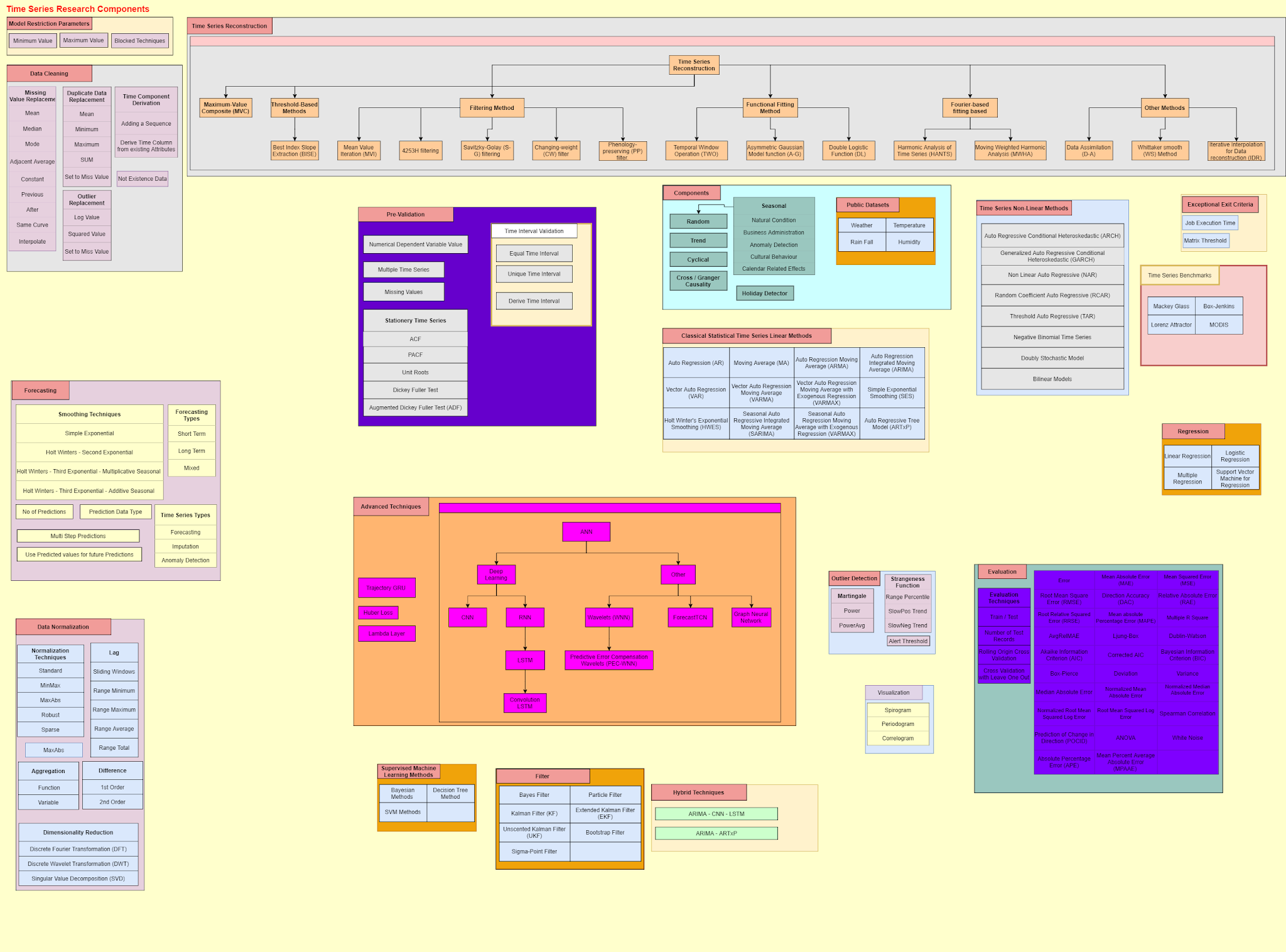
The Federalist Papers is a collection of 85 articles and essays written by Alexander Hamilton, James Madison, and John Jay. 1787 after the UK was thrown out from US, many were in the view that 13 counties should rule independently.
John Jay, James Madison, Alexander Hamilton wrote letters independently to pursue that the US should have a strong central government with the individual state government. Between 1787 - 1788 these papers were published under the pseudonym PUBLIS. While the authorship of 73 of The Federalist essays is fairly certain, the identities of those who wrote the twelve remaining essays are disputed by some scholars. In 1963 this dispute was fixed by Mosteller and Wallace using Bayesian Methods.
Let us see do a simple analysis of these papers by performing a analyse of the titles of these papers using the Orange Data Mining Tool. You can retrieve the sample files and the Orange workflow from dineshasanka/FederalistPapersOrangeDataMining (github.com).
Following is the Orange Data Mining workflow and let us go through important controls.