We are into the business end of the sporting event, FIFA 2022. As we have been doing for last couple of weeks, let us evaluate the Oxfor MAthematical Model. Even though the much anticipated semi-finals are yet to be kicked off, we can do the full evaluation. It is because, even now we know that the oxford predication for the final wont be a correct, as Brazil and belgium are out of the competition.
Let us analysis the stage wise accuracy rates.
Problem with this accuracy calculation is that the error is propagated. Since Oxford predicted that the Belgium will feature in the final in which they were out of the competition from the first round, that is reflected at every stage.
Would you accept this model with just over 50% of accuracy. That means it is just over the ad-hoc probability prediction. As we have been insisting, predicting the results outcome of a sport event, is not yet successful, it least for the moment.
We have been discussing the FIFA results prediction that was developed by Oxford University. Since the first round is completed, we can now do a model evaluation with the actual data vs. predicted data. Oxford mathematical model has two components, predicting the teams for the next round and the teams' position at each group.
As we saw in FIFA 2022, there were many surprises. While Japan, Australia, Morocco, and South Korea advanced to the next round, we saw Belgium (The number 2 ranked team), four times champions, and Germany out of the world cup in the first round.
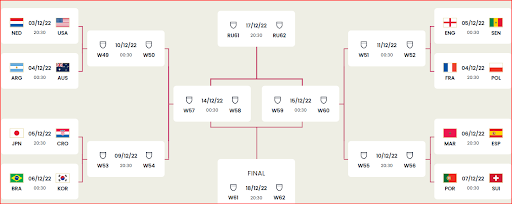
Following is the final 16s.
Out of the Oxford predictions for the next round, 9 out of 16 are correct, which is 65% of accuracy. Let us look at the group-wise rankings. Out of the 32 positions, only 11 were correct, meaning the accuracy is less than 35%.
When the group-wise analysis was made. All Group F position predictions were wrong, while there are no groups that all positions are correct.
When the position analysis was made, there were a few notable observations.
We can see a higher accuracy for positions 1 and 4. That means it is easy to predict the best and poorest teams. This is not again a hard part. However, their model could be better when predicting the number 2 and 3 positions. In fact, the number 3 position prediction accuracy is 9%.
Sport is all about fractions, inches, and moments. That is where the prediction of results is not difficult but impossible. If it is possible, it is not a sport.
No matter what level of mathematical models you can build, still predicting the result of a sport is extremely difficult, if not impossible. FIFA 2022 started with a lot of predictions, and we are just into the 4th day and 12th match, yet we have watched the two greatest upsets in the FIFA world cup.
The first, I would say it is the greatest upset of all time in which Saudi Arabia won against Messi's Argentina.
At the end of the first half, Argentina was leading 1-0, but in the next half, the oil nation scored two goals quickly. After the Saudi's first goal, the Argentinian giants were in disarray. In the end, most of the analytics said that crowd support for Saudi Arabia was one of the reasons for their surprising win.
The second match was between Japan and four times world cup winners (1954, 1974, 1990, 2014) Germany.
Germany was showing their class during the first half and scored the first goal. Germany has never lost a world cup match after 1954 after scoring the first goal. On the other hand, Japan has never won a world cup match after conceding a first goal. Even though statistics were not on their side, Japan won the match against Germany with a score line of 2-1. After the match, the analytics said that most of the Japanese players had played in the German football cup, which gave them an advantage over Germany.
How can we include crowd support and players' special features into mathematical modeling? I would say it is difficult, which is why sport is such an unpredictable and, thus, fantastic event. We can enjoy sports events only because of their unpredictable nature. If not, sport is not a sport, and let the sport be a sport.
After the Olympics, the world's most famous sporting event will raise its curtain today at Quater. The FIFA 2022 will be kicked off with 32 teams, and the obvious question would be "Who will be the winner". Will it be Brazil, Netherlands, Spain, Argentina, France, England, Belgium, or any other dark horses?
If you remember in FIFA 2010, Paul the Octopus predicted all the winners of the matches that involved Germany and the final between Spain and the Netherlands with an accuracy of 100%.
Paul the Octopus made friends and enemies on his own due to the predictions he made. Now in 2022, the University of Oxford has come up with a mathematical model to predict the winner.
The following figure is its prediction from the round of 16s.
According to the Oxford model, Brazil is the ultimate winner. However, looking at the recent, it will be a surprise.
Further, after 1998 defending champions did not perform well in the world cup finals. So France to be in the semi-finals is something against recent data.
I personally do not believe that predictions can be made for sports concerning its outcome. If you do that, I believe that will be the end of sports. Sport is beautiful because of the extremely high uncertainty. One touch or one move or one wrong decision may change the cause of the game drastically. In 2002 FIFA saw a lot of such matches. Who would have expected the defending champion, France to be beaten by the African nation Senegal? Who would have thought France would be out of the world cup in the first round without any wins? Among all the surprises, South Korea made the headlines by reaching the Semifinals and becoming the giant killer of Poland, Portugal, Italy, and Spain.
Predictions are part and parcel of our life. With more available data, we are looking at driven predictions rather than sense-driven predictions. Predication has expanded many domains such as ecomics, productions, sports etc. However, last week, we saw two of such predictions went wrong.
1. Whether predictions at T20I worldcup
First of all, pre-world cup favorites, India couldn't win the semi final while another pre tournmennt favorite, hosts, Aurtralia couldn't make even to the semi final. I am not going to consider that a wrong predictions as win/loss prediction in sports should fail in order to sport become more attractive.
However, when England - Pakistan lock horns with each other at the Melbourne for the final, there were predictions that match will not be possible to stage due to rain. There was 95% probability for rain. Playing conditions were altered in order to accommodate rain. Additonal day was already announced even before the tournament. But with the prediction of rain, match duration was increased by two hours and ten overs were set to constitute a match. However, match was played without any interruptions. There was a harmless drizzle for five to ten minutes.
What was Predicted
What was Actual
2. USA Mid Term Elections
Then the next prediction in USA mid term elections. It was expected to trump led republican to take over the senate, house and even the govenership easily. There was prediction of "red - wave" and trump's come back.. But at the end of the election, demoract was able to hold the power of senete with 50/50. (With the vice president twi breaker, they are narrowly holding the senete by one vote. Predications were expecting republicans to win 55 seats in senete. On the House, republicans were expecting to get 235 seats but they got 218 which is the cut of margin to win the state. (five seats yet to be called). Now many media organizations are calling to review the pre-election predictions.
I have been teaching at various places, and I have been using a few different techniques. I had never used Role Playing teaching technique until yesterday. It was totally sudden and was never in the plan.
I was teaching Data warehousing and wanted to explain the difficulty in requirement elicitation for data warehousing. The whole idea was to tell students that due to the ad-hoc data analysis in data warehousing it is difficult to collect requirements.
Roles
This is a postgraduate course where participants have some level of industry experience. In the class, there was a person who was a Human Resources Manager from a software development organization and there were two Business Analysts. There were a few developers as well. I asked Human Resource Manager to come up with a scenario, and instantly, he decided on employee attrition which seems to be a headache for the software industry these days.
So two BA were asked to find requirements for attrition analysis. Both parties started the discussion and no one knew where to start and what is the direction. During the 5 - 10 minutes discussion, it was very clear that the discussion was not focused. After completing the requirement elicitation, I asked BA to explain the requirements to the developer. Even though it was done, I am pretty much sure that the developer will not be able to develop an analytical solution for attrition.
Then the second role-playing started. I asked the same BA team to capture requirements to implement an exit interview procedure. Then the BA team said that they can be a passive participant at the exit interview and they can collect exsitng document with related to the exit interviews. Then it was very clear that requirement capturing for that task is much simpler than the before task.
Experience Sharing
After the role playing was completed, I asked from each party, and the viewers' experience in the role playing. All agreed that requirement elicitation in analytical systems is difficult and needs more experience.
For me this was a new experience and it was sudden. Next time I need to plan for such events more methodically.
I am not sure whether they enjoyed, but I really did enjoy.
This is a post that was shared in LinkedIn and thought of exploring this with my pet tool Orange Data Mining tool.
First, separate these images into single images randomly. Since there is a small number of images, thought of employing clustering over classification.
Following is the very simple Orange flow and it can be found at GitHub as well.
As you could see, it is a very simple Orange workflow. Inception v3 was used as the embedded and Cosine distance was used as the distance calculation. Then Hierarchical Clustering was used. it is as very clear clusters which can be seen in the following figure.
Then the cluster distribution as below.
So, you can't confuse Machine Learning as you think.
Python in SQL Server is an important feature that is provided especially for data scientists. However, there are additional libraries that you need to install to achieve your goals. statsmodels is a Python module that provides classes and functions for the estimation of many different statistical models, as well as for conducting statistical tests and statistical data exploration.
In statmodels, there are multiple versions and you need to pick the right version for you. For example, STL is available only after 0.12.0 statmodels. By default SQL Server 2019 will get you the statmodels 0.9.0 which may not be enough so you have to upgrade which can be done from the following python pip.
python -m pip install statsmodels
However, this will give you an error saying that you need to upgrade the python to the higher version of 3.8 as SQL Server as the python 3.7.1 version. Now you need to upgrade python for SQL Server.
But the better thing to do is to upgrading relevant statsmodels version which is 0.12.0. Therefore you need to run the commandpython -m pip install statsmodels==0.12.0at the folder.
Testing is a challenging task in Data Warehousing. This article provides methods and scripts for performing testing on the Slowly Changing Dimensions (SCD).
We have been discussing ETLs in detail for the data warehouse. As you know, in ETL one of the important task is extracting the incremental data extraction from sources. This article discusses a new method to extract data from operational databases and how to use ETL using Database snapshots in order to improve the ETL process.