Clustering is often used to identify natural groups in a dataset. Since the clustering technique does not depend on any independent variable, the clustering technique is said to be unsupervised learning. The classification technique is supervised as it models data for a target or dependent variable. This post describes clustering as a pre-processing task for classification. This post has used the Orange Data Mining tool to demonstrate the above scenario.
Following is the complete orange data mining workflow, and this is available in the Git Hub as well.

The attrition sample dataset is used to demonstrate the above scenario. This dataset contains 18 variables with 1470 instances. Then the Jaccard distance is used, and it is essential to remember that you may have to choose a different distance technique in order to improve the results.

Then hierarchical clustering is used for three clusters as too many clustering will have smaller clusters and may cause overfitting. Following is the cluster distribution for the three clusters.
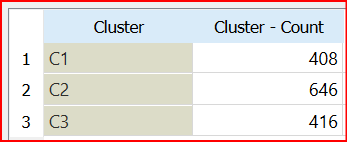
After the clustering is completed, the dataset is selected for each cluster and unnecessary columns (Clsuter and Selected) are removed. Then for each cluster, different classification techniques were executed. This scenario uses SVM, Logistic Regression, Neural Network, Random Forest, AdaBoost, Naive Bayes, Tree, and kNN classification techniques.
When classification techniques were executed for the entire dataset, without clustering, the best classification technique was Logistic Regression with a Classification accuracy of 87%.
Following are the classification accuracies and other evaluation parameters for each cluster once it is evaluated with all the above said eight different classification techniques.

The above table shows that C1 and C2 clusters have higher accuracy than the full dataset. However, the third cluster performance is not as good as the overall dataset classification.
This technique is better when there are large volumes of data if not clustering will reduce the data which can lead to model overfitting.
No comments:
Post a Comment