Sentiment Analysis has become an important as well as tedious Business Task in order to explain how customers think about different products and services.
Apart from simple sentiment analysis, you would like to know what makes your product better or worst so that you improve your products and services. Classification Association Rule (CAR) is used to find what makes your product positive or negative.
WEKA supports the CAR option in association and let's see how we can utilize this feature.
We have used the Film review dataset which has 2000 reviews for 1000 each for positive and negative reviews.
By using, String to Word Vector in Weka, texts were converted to Binary Vector and Loving Stemmer, Rainbow stopwords and Alphabetic Tokenizer were used.
In order to support, Association Rule in WEKA data set was modified and can be downloaded here.
The sample of data is here.
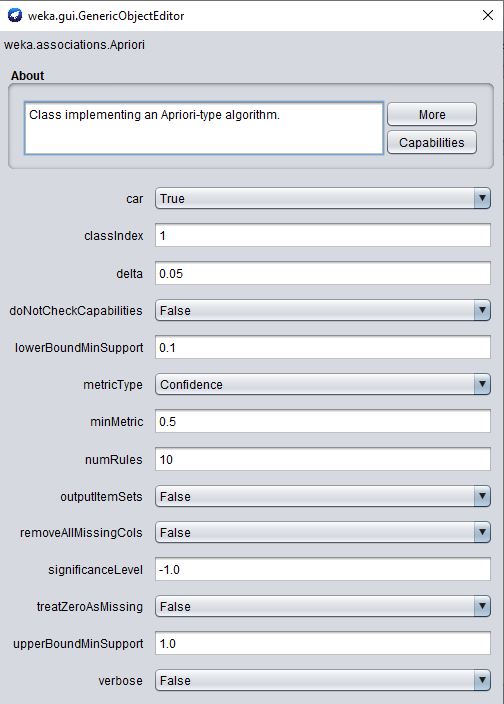
Apriori algorithm is used to find the association rules with changes as shown below.
In the above configuration, the CAR option set to TRUE and the class index is set 1. The class index indicates, what is the index of the class parameter. Since it is the first parameter in the dataset, 1 is selected. minMetric also set 0.5 as we may not have rules for higher confidence values.
Let us see the results.
What do these rules say? If you look at rule 2 when the text "movie" exits review is negative. Please note that "movie" text is stammered to "movi" . The rules such as 3, 4, 5, and 8 say, text "film" tends to indicate positive review.
This is an astonishing finding as film and movie are synonyms but they tend to have completely different sentiments.